원하는 이미지를 가지고 합성하는 연구는 꾸준히 진행되고 있다. 저자들은 기존 연구들이 레퍼런스 이미지와의 similarity와 프롬프트대로 합성하는 controllability 사이에서 상충한다는 dual-optimum 패러독스 때문에 합성이 제대로 되지 않는다는 문제점을 발견했고, 이를 해결하기 위해 RealCustom 아키텍처를 제안했다.
기존 연구들의 한계점과 이를 해결하기 위해 저자들이 제안한 방법을 알아보겠다.

기존 방법의 한계점
앞서 얘기한 것처럼, 기존 유사한 연구들은 레퍼런스 이미지와의 similarity와 프롬프트대로 합성하는 controllability 를 모두 충족시키지 못하고, 저자들은 이를 dual-optimum 패러독스라고 명명했다. 저자들은 그 원인을 sks나 vkv 같은 pseudo-token을 이용한 파인튜닝이라고 봤는데, pseudo-token이 similarity와 controllability를 entangle 함으로써 각각의 최적화를 방해하기 때문이라고 주장한다.
아이디어
Pseudo-token에 해당하는 concept은 일치하면서도 배경이나 포즈, 스타일 등은 달라져야 하는데, pseudo-token을 사용해 학습하면 해당 토큰과 프롬프트의 다른 부분들이 이미지에 동시에 영향을 미치기 때문에 이를 분리해줘야 한다고 생각했고, 그래서 저자들은 학습하는 동안에는 레퍼런스 이미지의 generalized visual feature와 텍스트 프롬프트 사이의 alignment를 학습하도록 도와주는 adaptive scoring module을 제안한다. 또한, inference 때에는 adaptive mask guidance strategy를 이용해 앞에서 학습한 alignment를 좁혀가는 방법으로 이미지를 생성한다.
Adaptive scoring module
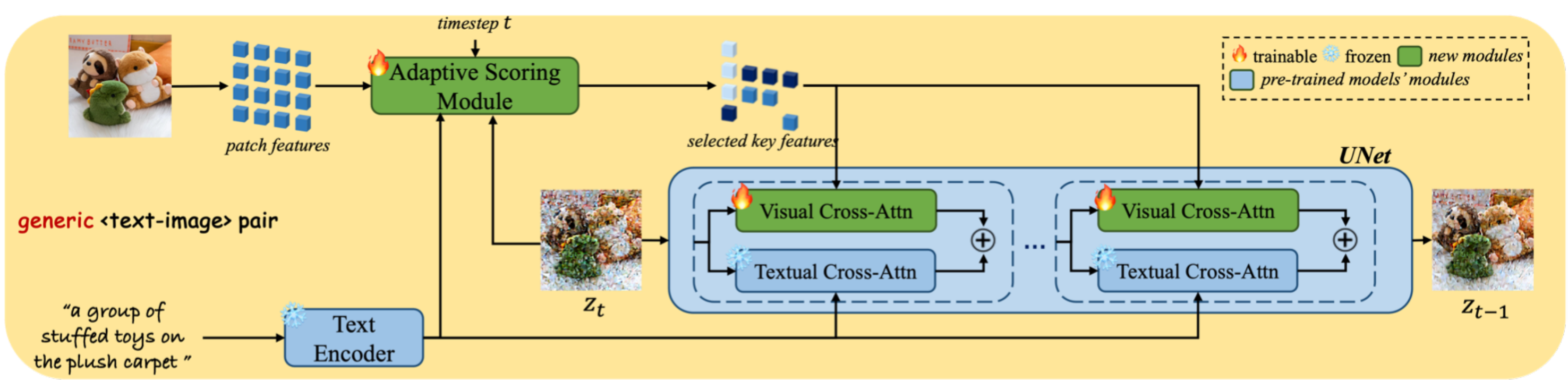
학습이 진행되는 동안에는 위 그림과 같이 text feature와 image feature의 pair를 adaptive scoring module과 projection layer를 통해 projection한 값을 cross attention 모듈에 넣어준다. 학습과정과 inference 사이에는 큰 차이가 있는데, 일반적으로 학습과정은 입력된 이미지를 그대로 그려내도록 학습되지만, inference과정은 해당 concept에 해당하는 부분만 일치하고 이외에 부분은 프롬프트에 영향을 받아야 하기 때문이다. 이러한 train-inference 간의 gap 때문에 visual feature를 그대로 input으로 사용하게 되면 subject의 identity를 잘 그려낼 수 없게 된다.
그래서 저자들은 visual feature를 그대로 넣기보다 adaptive scoring module에서 image feature에 generated feature와 text feature를 각각 결합해 각각의 score를 고려해 feature를 뽑는 방법을 제안했다.

Adaptive mask strategy at Inference step
Inference step에서는 생성된 이미지 중 subject에 해당되는 부분이 reference와 일치하는지를 확인해야 한다. Cross attention map을 이용하는데, 추출된 cross attention map과 매 timestep마다 generated 된 이미지를 곱해 해당 부분에 attention 매커니즘을 이용해 계속 업데이트되도록 이미지 퀄리티를 높여주는 방법을 제안했다.
결론
Tokenizer에 없는 새로운 pseudo-token을 활용한 방법은 굉장히 널리 쓰이는 방법이지만, 해당 방법의 문제점을 분석하고 극복하기 위한 방법을 제안했다. 코드가 없어 논문에 주장되는 결과를 빠르게 reproduce해볼 수 없는 것은 아쉽지만, subject를 generate하는 점에서 실용적인 논문이다.



