Dreambooth, Textual Inversion 등으로 대표되는 stable diffusion과 같은 foundataion 모델에서 학습하지 않은 custom concept을 적은 데이터셋으로 학습해 원하는 이미지를 만드는 연구는 계속되고 있지만, 특히 여러개의 concept에 대해 제대로 합성하지 못하는 한계점이 많이 보인다. 또한, 여러장의 데이터가 필요한데, MS-Diffusion에서 저자들은 zero shot 환경에서 concept들의 디테일한 부분과 위에서 언급한 여러개의 concept을 제대로 합성하지 못하는 문제를 해결하고자 했다.
MS-Diffusion의 저자들 어떠한 문제점을 어떻게 해결했는지 아래에 간단히 살펴보겠다.
해결하고자 하는 문제
Dreambooth로 대표되는 fine-tuning 방식들은 n장 (3~5장)의 reference이미지를 사용해 모델을 fine-tning한 후, 원하는 concept을 합성하기 때문에, 데이터와 학습 시간의 이슈가 있다. 이를 fine-tuning 과정 없이, zero-shot에서 합성하고자 하는 연구를 진행했다.
기존 방법의 한계점
원하는 concept들을 활용한 personalized 이미지를 위해, IP-Adapter 또는 ELITE 같은 선행연구들은 cross attention 매커니즘을 text와 이미지 feature 들에 각각 적용하는 방식으로 reference 이미지가 visual prompt로 바로 입력될 수 있게 되었다. 또한, SSR-Encoder 나 Emu, KOSMOS-G 같은 연구들은 multi-concept 을 해결하기 위한 시도를 하였는데, 아래 그림과 같이 한 가지의 concept만 합성되거나, concept이 섞이는 등 concept의 디테일을 제대로 살려주지 못하는 한계점을 보인다.

아이디어
저자들의 인사이트를 한마디로 정리하면, layout-guided zero-shot image personalization 이다. 즉, layout을 이용해 생성모델이 각각의 subject를 어디에 그려줄지를 guide함으로써 위에서 본 것과 같은 concept의 mixing이나 neglect를 방지하고자 했다.
이를 위해, concept들의 디테일한 feature를 뽑고 합치는 grounding-resampler와 여러개의 concept을 위한 cross-attention 매커니즘을 제안했다. 또한, multi-concept의 데이터를 위해 기존 방식과 다른 NER 프로토콜을 적용하여 데이터셋을 만들었다.
데이터 구성
기존의 multi-concept 에서의 합성을 해결하고자 한 연구들은 각각의 concept을 단순히 붙여 데이터를 합성했고, 때문에 copy-and-paste 된 것 같은 결과가 생성되었다. 이를 해결하기 위해, 비디오 데이터를 사용했고, 각기 다른 두 개의 프레임을 각각 subject을 뽑아내고, reference로 사용했다.
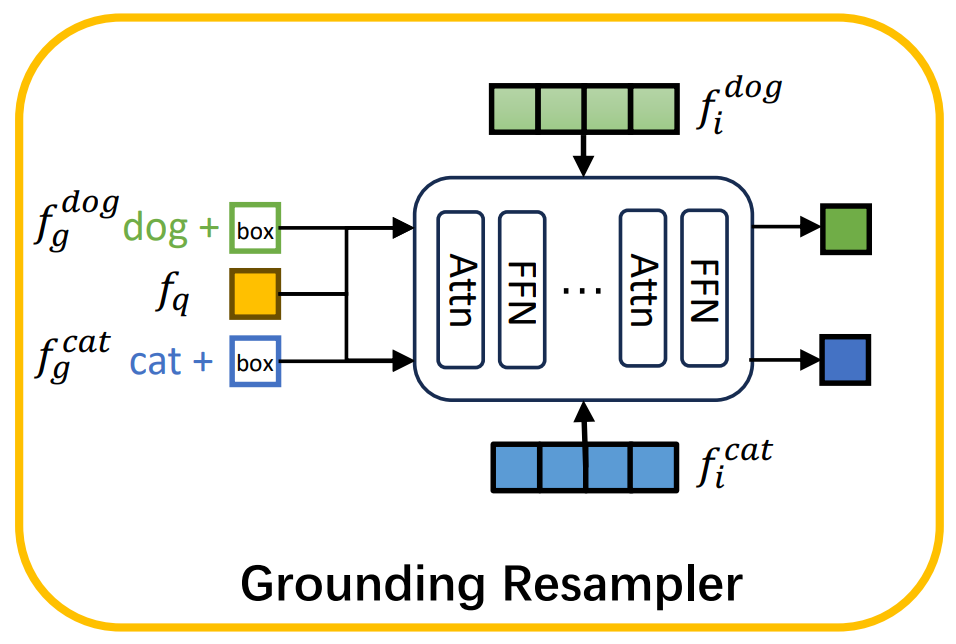
Grounding resampler
텍스트 embedding과 다르게, 이미지 embedding은 보다 많은 정보를 포함하고 있지만, 보다 sparse 하기 때문에, 새로운 embedding space로의 projection을 어렵게 만든다. 이미지 인코더에서 추출한 정보는 대부분의 디테일한 정보를 누락하는 경향이 있는데, 저자는 이를 해결하기 위해 grounding resampler를 제안한다.
Grounding resampler는 이미지의 feature를 추출하기보다, 해당 concept의 영역을 어텐션을 이용해 새로운 embedding으로 mapping하는 projection의 역할을 한다.
Multi-subject cross-attention
여러개의 concept이 섞인 이미지를 그릴 때, concept들이 섞이거나 프롬프트와 맞지 않을 수 있는데, 저자는 이를 attention mask를 활용해 해결했다. 특히, 각 concept이 layout 안에 그려지도록 attention mask를 제한해, 해당 영역에서만 그려지도록 강제했다.
결론
Layout이 필요하다는 한계점이 있지만, 이미지 encoder를 그대로 활용하지 않고, 이를 다른 embedding으로의 projection으로 활용해 각각의 subject들이 해당하는 cross attention map을 잘 가질 수 있도록 했다. 보다 복잡한 프롬프트에서의 생성과 영상 데이터가 필요하다는 점에서는 실용성 측면에서 한계점을 가질 것 같다.
유사한 연구를 다룬 다른 포스팅은 아래 글을 참고해주세요.
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
[1페이지 논문읽기] AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Dreambooth, Textual Inversion 등 stable diffusion과 같은 foundataion 모델에서 학습하지 않은 custom concept을 적은 데이터셋으로 학습해 원하는 이미지를 만드는 연구는 계속되고 있지만, 여전히 프롬프트에 맞
contentstailor.com



