기존의 foundation 모델들은 multi object를 생성하는데 어려움을 겪고 있다. 예를 들어, 아래 그림에서 보듯, "초록색 옷을 입고 있는 토끼와 빨간 모자를 쓴 여우"를 그리라고 하면, 토끼만 두 마리를 그리거나 둘 다 초록색 옷을 입고 있는 이미지를 그려준다.
이러한 문제를 해결해 멀티 object의 생성을 보다 잘 하게 해주는 연구가 있어 소개해본다.
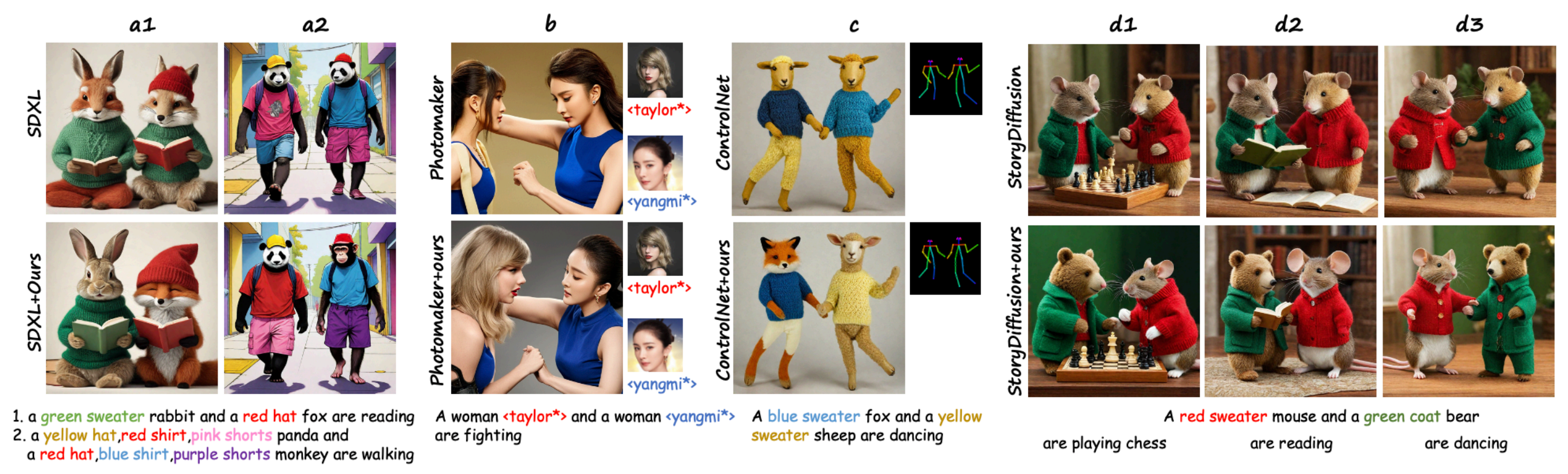
기존 연구의 문제점
서두에서 밝힌 것처럼, 기존 연구들은 object 간의 속성들이 섞이거나 제대로 그려지지 않는 "attribute confusion" 이슈가 있고, 이를 해결하기 위한 다양한 시도가 있었다.
몇몇 연구들에서는 inference 때 latent representation을 optimize해서 텍스트와 이미지간의 연관성을 강제했는데 이러한 latent representation 값을 바꾸는 것이 이미지의 품질을 떨어뜨렸다.
다른 연구들에서는 prompt를 나누어 각각 합성하는 시도를 했었는데, globa semantic을 캡처하는 것이 어려워 제대로된 합성이 이뤄지지 않았고, inference 시간까지 증가시켰다.
아이디어
저자들은 multi object 를 생성하는데 cross attention map이 겹치거나 영역을 제대로 감지하지 못할 때, attribute confusion이 생기는 것에 착안해 이를 강제해주는 SP-Mask 와 SP-Attn 을 제안한다.
SP-Mask
관계 없는 object 토큰들로부터 관계 있는 object 토큰들의 cross attention map을 구별하기 위해 SP-Mask 방법을 제안했는데, 이는 object들의 set과 region들의 set이 있을 때, object 하나당 region 하나씩이 매칭되어 다른 region들은 강제로 값을 0으로 고정한다.
그렇게되면, 관계된 영역만 object가 그려지게 된다.
처음에 cross attention map이 제대로 그려지지 않는 경우나 어떻게 object와 region pair가 만들어지는지에 대한 분석이나 방법이 추가되면 보다 좋았을 것 같다.
SP-Attn
위에서 뽑아낸 SP-Mask를 가지고 unet의 attention layer에 넣어 연산을 진행한다. 기존의 cross attention을 SP-Attn으로 바꿔 SP-Mask에서 가이드하는 대로 이미지가 출력되게 한다.
느낀점
굉장히 심플한 아이디어이고, 유사한 아이디어를 제안한 연구도 많이 있는데, multi object generation task에서 기존의 방법들이 시도하지 않은 방법을 잘 적용한 것 같다.
(Mask를 강제한다는 아이디어가 너무 심플하다고 생각되어 시도하지 않았던 걸수도 있지만.. )
이미지를 만들 때, attribute들이 겹치는 경우도 많이 있다. 자동차에 탄 강아지나 핑크 선글라스를 낀 고양이 등등. 이런 경우에도 저자들의 방법이 잘 작동할 수 있을지에 대한 설명도 있었으면 좋았을 것 같다.
예시 이미지에도 이러한 결과가 없는 것은 아쉽다.
