기존 optimization-based 튜닝 방법과 direct-regression 방법의 장점을 합친 HybridBooth 아키텍처를 제안한다. 이 논문에서 저자들은 word embedding을 잘 refine해서 subject-driven generation task를 해결했다고 주장한다.
어떠한 아이디어로 어떻게 문제를 해결했는지 알아보겠다.

기존 연구의 한계점
기존 연구는 크게 보면, 여러장의 이미지를 입력으로 받아 fine-tuning 하는 optimization-based 튜닝 방법과 다량의 데이터에서 pretrained된 모델과 이미지 한장을 이용해 이미지를 그려내는 direct-regression 방법으로 나눌 수 있는데, 각각 정확성과 속도의 장점을 가지고 있지만, 역시 속도와 정확성이라는 단점을 서로 가지고 있다. 때문에 저자들은 속도와 정확성의 장점을 결합해 빠르게 디테일한 부분까지 생성하는 아키텍처를 제안한다.

아이디어
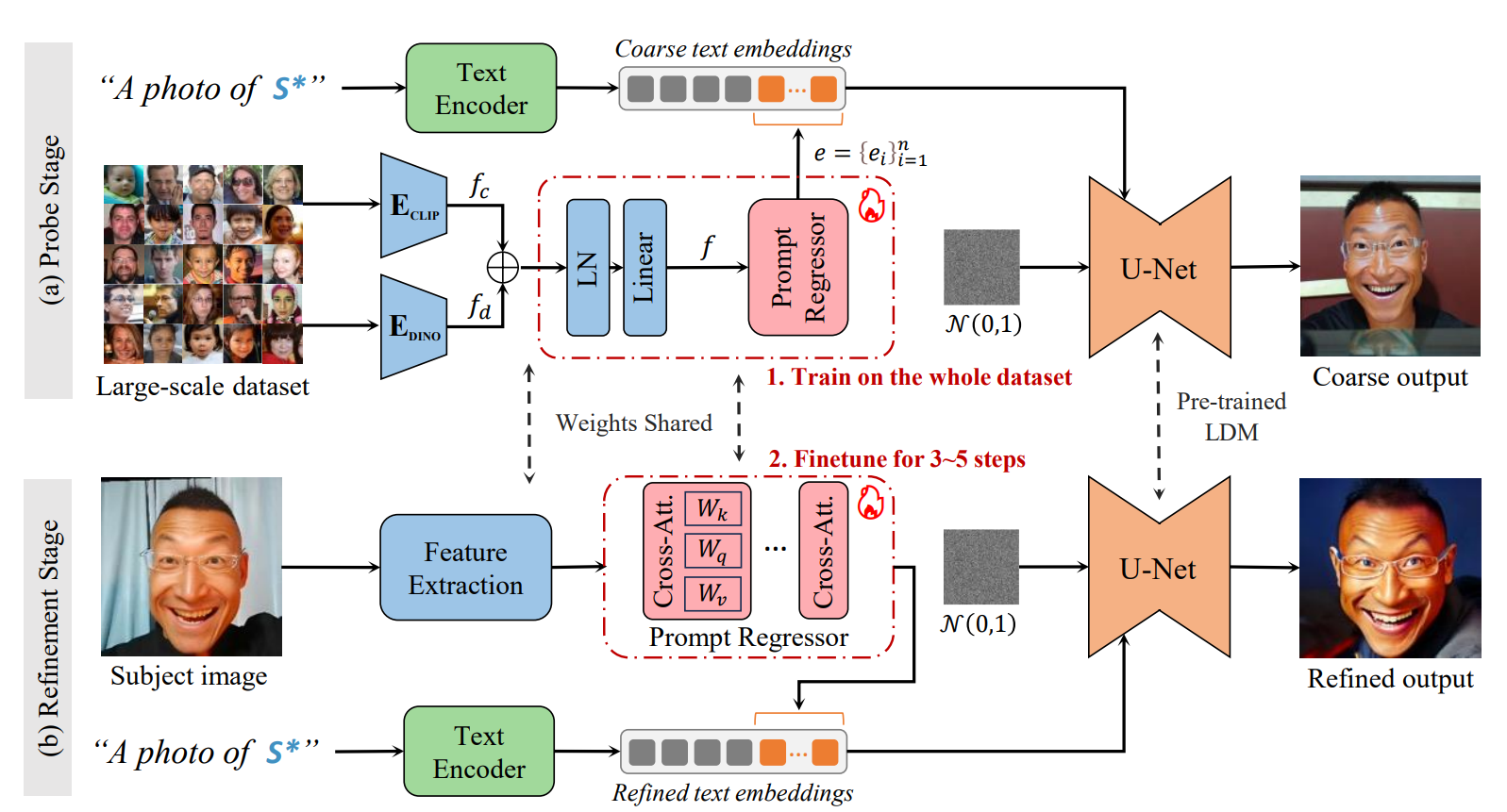
위 그림에서 나온 것처럼 Proble stage와 Refinement stage 두 단계로 나누어진다. Probe stage에서는 initial word embedding을 학습하고, 이렇게 학습한 initial word embedding을 refinement stage에서 튜닝한 후, 이미지를 만들어내게 된다. 이로 해 저자들은 probe stage에서 전체 데이터에 학습 후 coarse한 embedding을 뽑을 수 있기 때문에, inference 즉, refinement stage에서는 3~5 step 안에 optimization이 가능하다고 주장하고 있다.
결론
두 가지를 결합할 경우 두 방법의 단점이 부각될 것이라고 생각했는데, 저자들의 연구는 그것을 뛰어넘어 각각의 장점을 결합했다. CLIP feature 대신 DINO feature를 사용하거나 디테일한 내용을 살리기 위해 residual refinement를 사용하는 등 디테일한 구현에도 신경을 썼는데, reproduce를 통해 실제 결과가 어느정도 나오는지 확인해봐야겠다.